AWSで仮想IPを実現する方法4選
なんだかんだ言ってもAWSで昔ながらのクラスタ方式をやりたくて仮想IP欲しいって時あります。
AWSではまだ仮想IPという機能そのものは提供されていません。
また、仮想IPを実現するための重要な技術ARPもAWSというかVPCでは特殊な実装になっており、オンプレのようには動作しません。そこでAWSならではの方法でなんとか実現することになります。
以下4つの方式について書きます。
- EIP方式
- VIP方式
- DNS方式
- ELB方式
ここではその実装方法まで紹介します。
切り替え動作としてサービス側でヘルスチェックし切り替えということもできますが、ここでは昔ながらのクラスタ方式を考えているので、クラスタリングツール主導で切り替えを行うことを想定しています。そのため、模擬としてEventBridge(Cloudwatch)でフェイルオーバーすべきイベントを検知したのちlambdaから切り替えのためのAPI実行という流れで実装例を紹介しています。
サマリの表です。
| 実現可能性 | メリット | デメリット | |
| EIP方式 | 容易 | 手軽に実現可能 | ・仮想IPがグローバルIPとなる ・lambda等用意する必要がある |
| VIP方式 | ✕(今回できなかった) | プライベートIPを仮想IPとできる | ・VPC内でのみ有効 ・OS側でも設定が必要 |
| DNS方式 | 容易だが、DNS環境によっては複雑になる | ・手軽 ・プライベートIPで実現できる | ・IPではなくFQDNを用いる必要がある ・クライアント側のDNSサーバ次第では実現不可 ・TTL次第では切り替えに時間が掛かる可能性がある |
| ELB方式 | やや面倒 | プライベートIPで実現できる | ・IPではなくFQDNを用いる必要がある ・クライアント側のDNSサーバ次第では実現不可 ・ターゲットをこちらで切り離し・登録する場合反映に5分程度掛かる ・ポート番号をいちいち設定するのが面倒 |
Contents
EIP方式
Elastic IP addressを使った方式で、通常時はプライマリ機にEIPを関連付けし、障害時にはセカンダリ機にEIPを付け替えすることで同じEIPを使って継続して処理を行えるようにします。EIPなのでグローバルIPを使うことになるのでルーティングに注意が必要です。

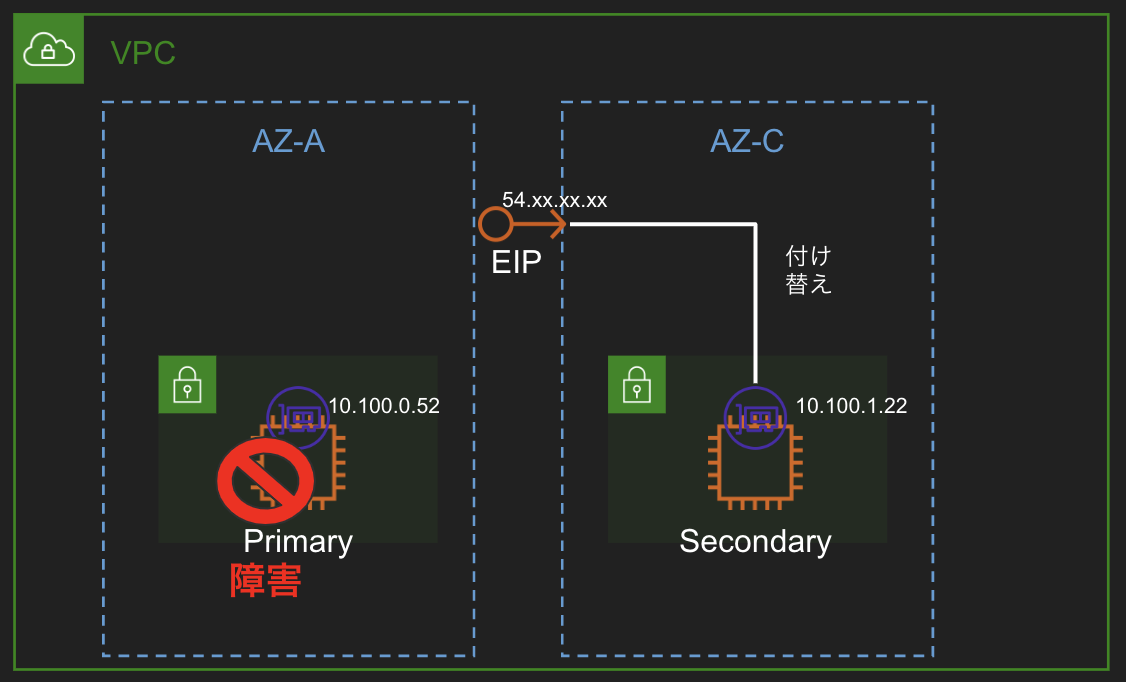
実装例
実際に試してみます。EventBridge(Cloudwatch Events)でフェイルオーバーすべきイベントを検知したのちlambdaからEIP切り替えのためのAPI実行という流れです。本来はクラスタリングソフトからlambda起動かと思います。
EC2のデプロイとプライマリへのEIP関連付けはすでに行っている前提で書きます。
ID取得
EIPの切り替え動作を行うために、EIPのallocation IDとENIのIDが必要となります。
プライマリのインスタンスをクリックし、ネットワーキングタブのとこからEIPのallocation ID(下記画像の割り当てID部分)を取得します。その後、セカンダリのインスタンスのENIのID(下記画像のインターフェイスID部分)も取得します。これはあとでlamdbaの環境変数に使います。
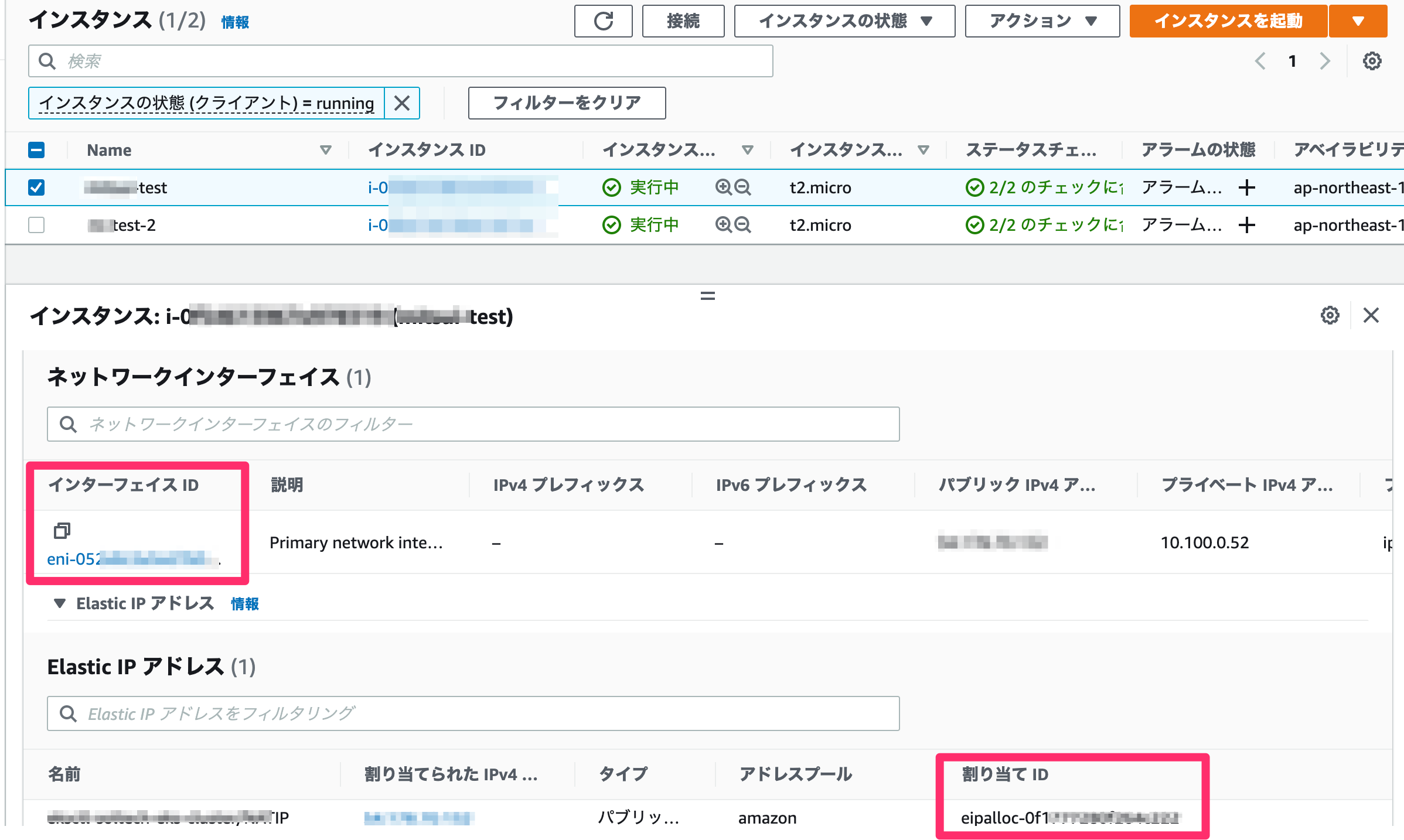
lambda作成
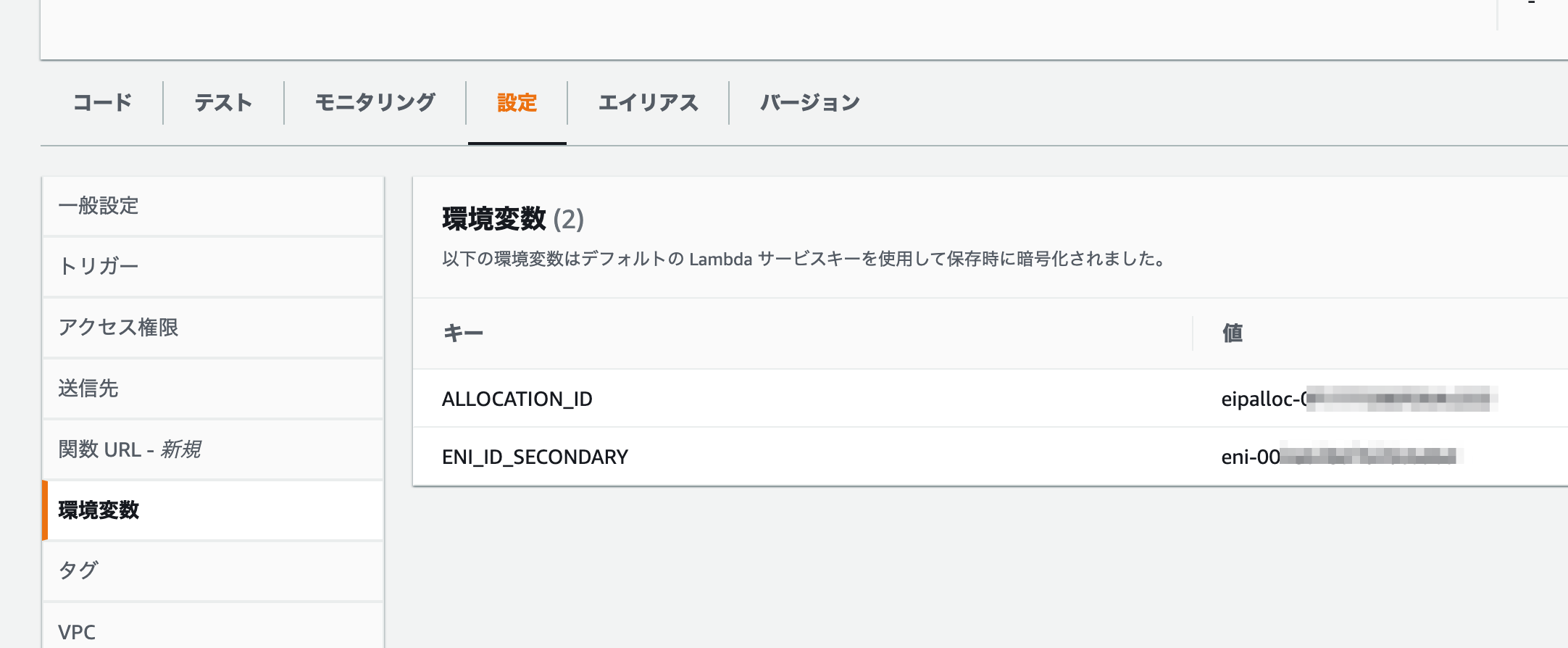
新規にlambda関数を作成します。ランタイムをPythonにし、「AmazonEC2FullAccess」のポリシーをつけたIAMロールをつけます。*AmazonEC2FullAccessのポリシーは権限の範囲が広すぎるので本来はassociate_addressだけ実行できる権限に絞っておくべきです。

コードを以下に修正します。今回は例ですし、エラーになってもcloudwatchでログ見れるのであえてtry-exceptはしていないので必要な方はカスタマイズしてください。
disassociate_addressという関連付けを解除するメソッドも用意されていますが、associate_addressは現在関連付けがされているENIからEIPを剥がして、新しいENIへ関連付けをしてくれるのでassociate_addressだけ実行すればOKです。
import json
import boto3
import os
def lambda_handler(event, context):
ec2 = boto3.client('ec2', region_name='ap-northeast-1')
ALLOCATION_ID = os.environ['ALLOCATION_ID']
ENI_ID_SECONDARY = os.environ['ENI_ID_SECONDARY']
associate = ec2.associate_address(
AllocationId=ALLOCATION_ID,
NetworkInterfaceId=ENI_ID_SECONDARY
)
return {
'statusCode': 200,
'body': json.dumps(associate)
}環境変数にEIPの割当IDとセカンダリインスタンスのENIのIDを設定します。
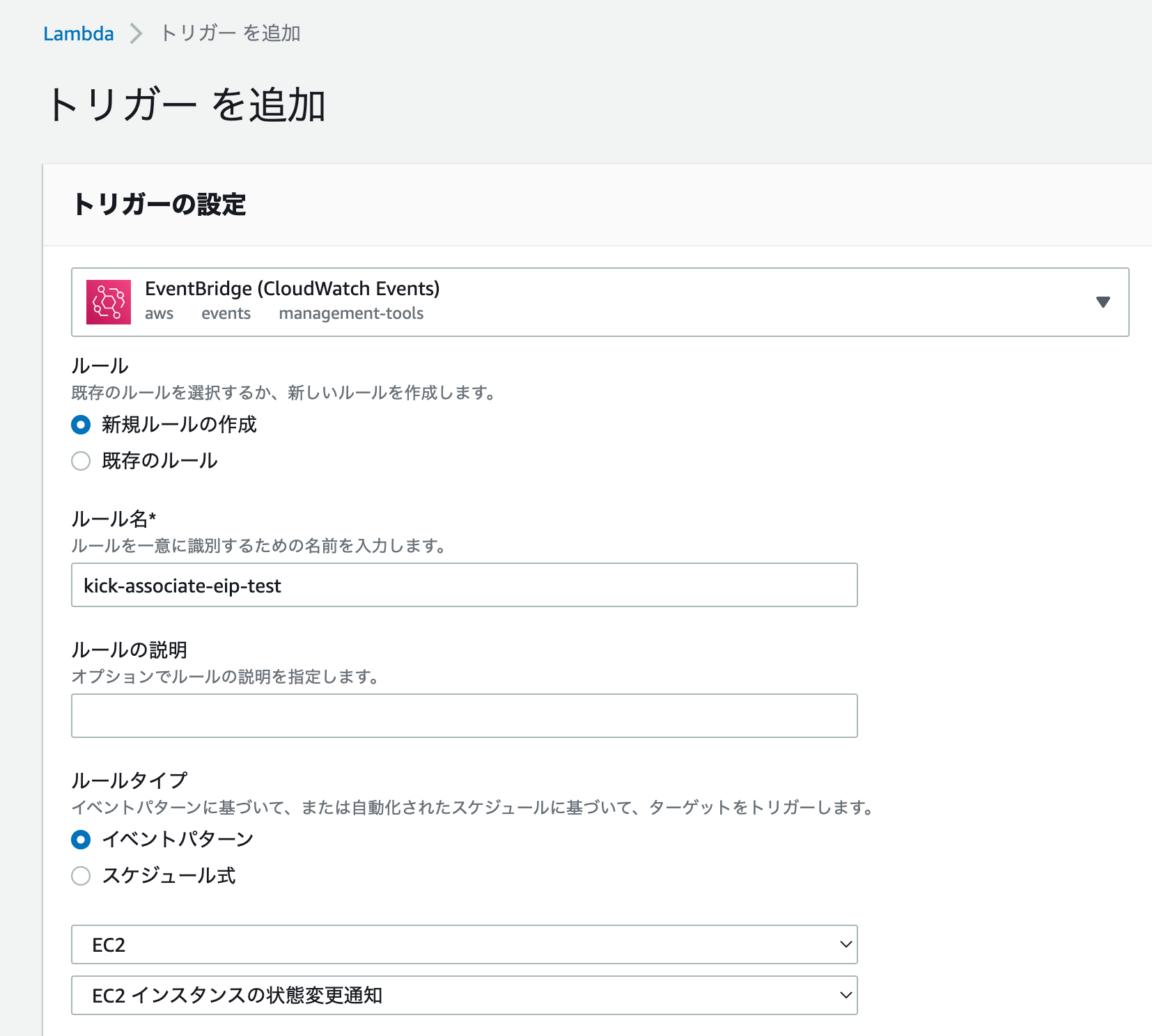
トリガー設定
設定->トリガー、からトリガーを追加。EventBridgeを使ってプライマリEC2インスタンスが停止した際にこのlambdaを実行するようにします。
インスタンスIDにはプライマリインスタンスのインスタンスIDを指定します。
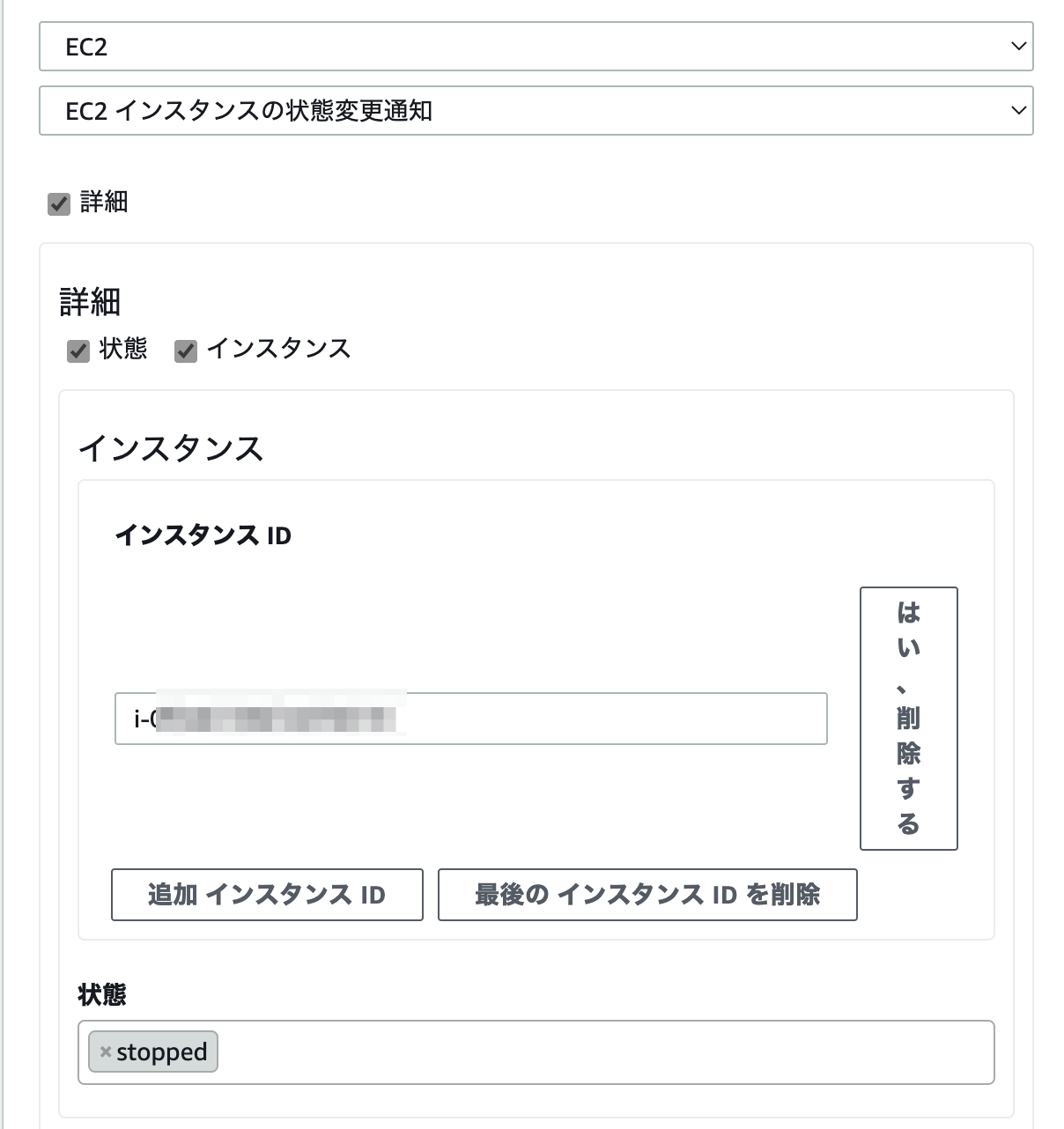

テスト
プライマリ側のインスタンスを停止します。
すると、数秒後にはセカンダリのインスタンスにEIPがついていることが確認できるかと思います。今回はEventBridgeでインスタンスが停止したらすぐlambdaが実行されますし、EIPの関連付け、関連付けの削除は通常即時反映されるので数秒後にはもう切り替わります。
なお、先程lambda上で作成したトリガーはEventBridgeでルールとして作成されており、ちゃんとインスタンスの停止を契機にトリガーされたこともモニタリングから確認できます。
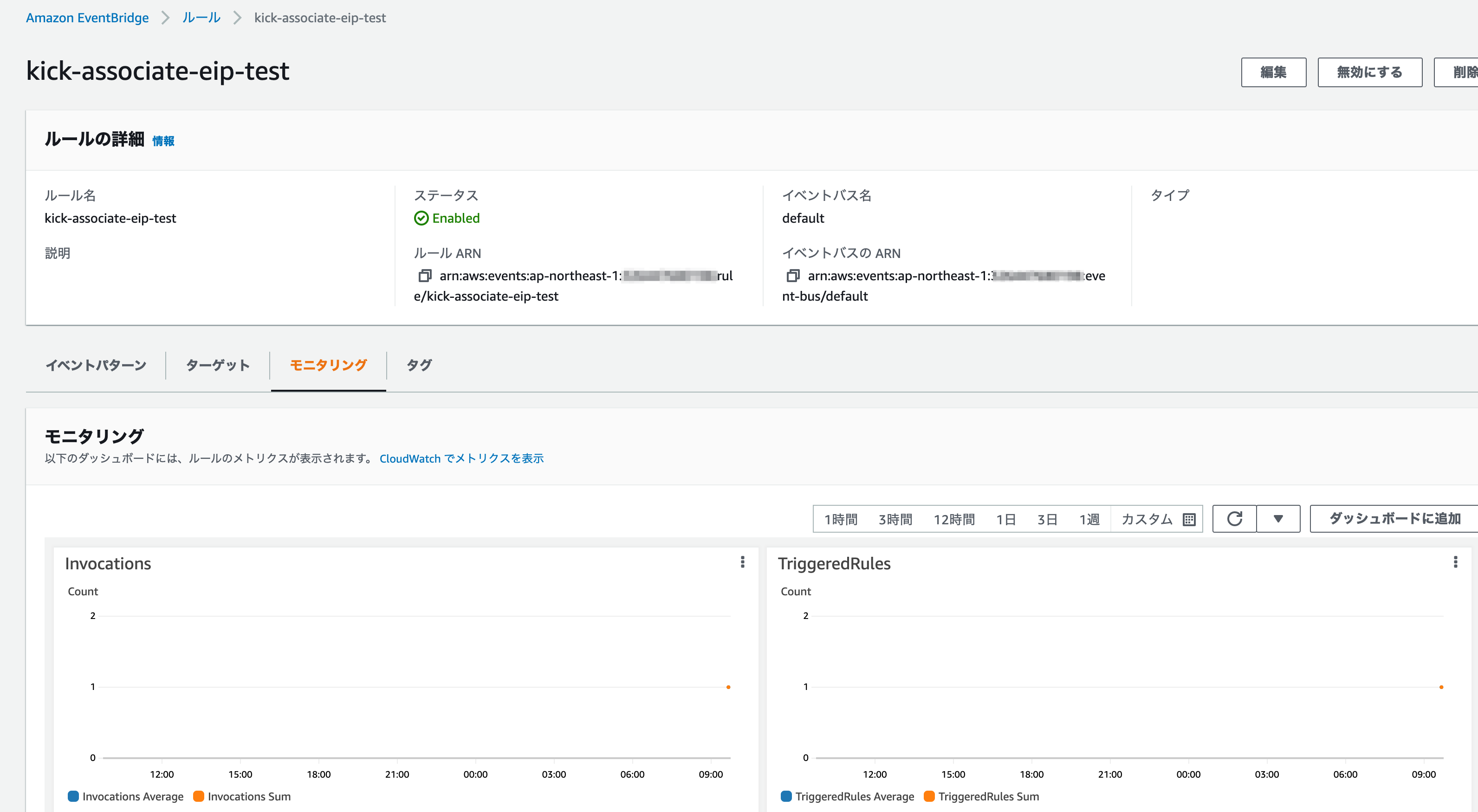
DNS方式
DNSサーバを使った方式で、IPではなく名前(FQDN)でアクセスするようにします。
通常時はそのFQDNとしてプライマリのIPを返すようにし、障害時にはセカンダリのIPを返すようにします。AWSなのでRoute53 プライベートホストゾーンを使うのが良いかと思います。プライベートホストゾーンは関連づけたVPCからのみ名前解決が可能になります。
Route53はプライベートホストゾーンでも名前解決のルーティングポリシーとしてfailoverが使用できます。つまりヘルスチェックを行い、失敗すればセカンダリのIPを返すようにできる機能をRoute53単体で実現可能です。ですが、昔ながらのクラスタリングを今回は意識しているので、その場合はクラスタリングツールから切り替えを指示したいのでlambdaから切り替えを行う方法を今回紹介します。
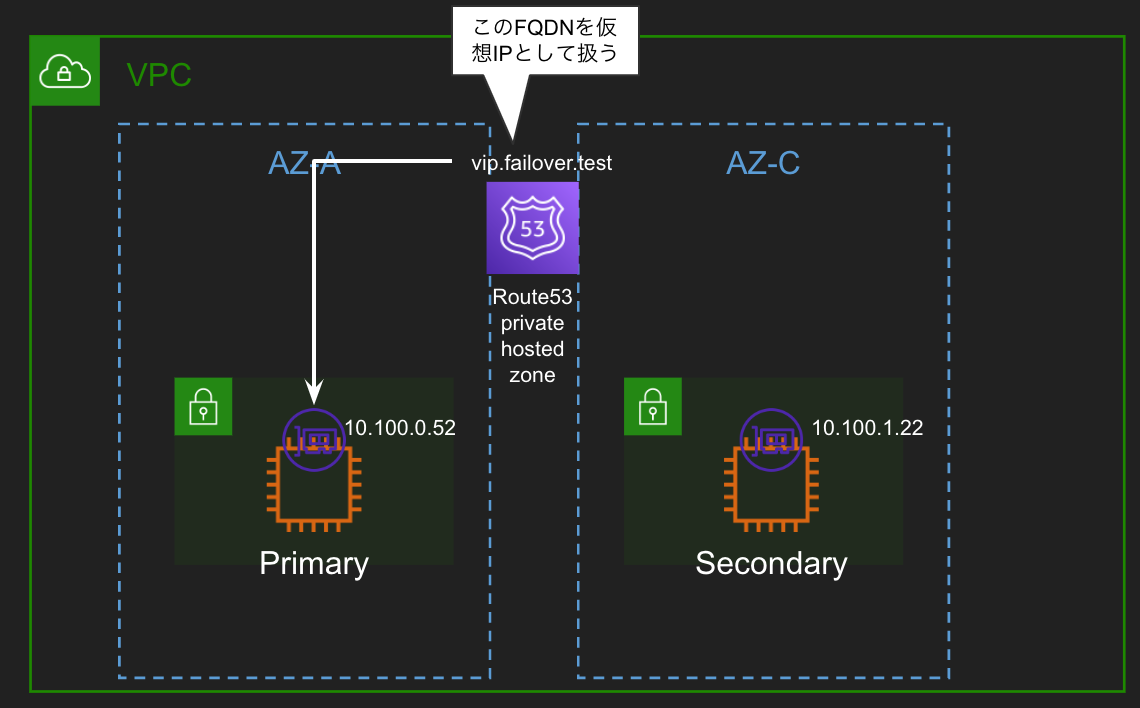

実装例
route53プライベートホストゾーンでFQDNを仮想IP代わりに使い、lambdaとEventBridgeでプライマリインスタンスのダウンを検知したらFQDNのIPをセカンダリのIPに変えます。
Route53作成
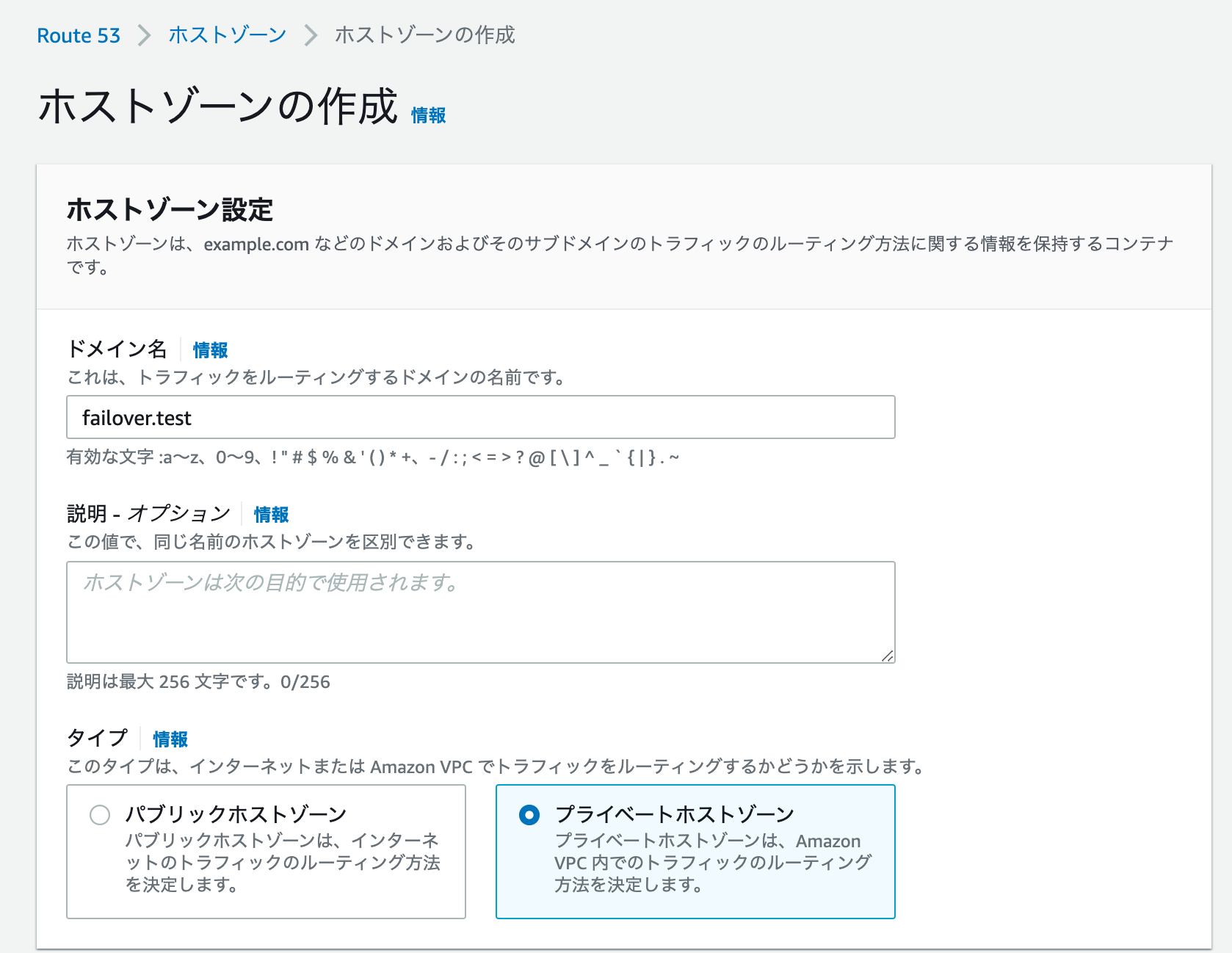
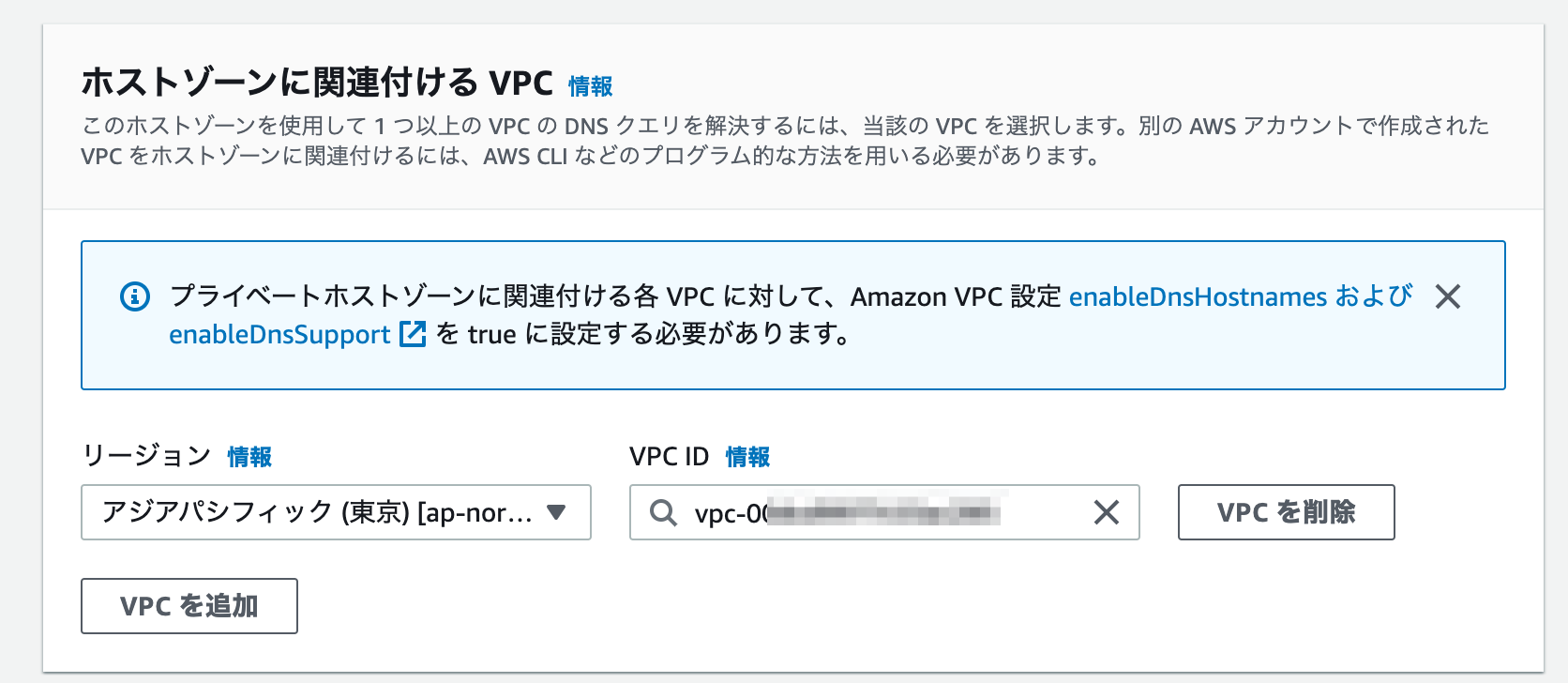
上記設定でプライベートホストゾーンを作成。1分くらいできました。
次にVIP的に使う使うレコードを追加します。切り替えを早くするためにTTLを60にします。
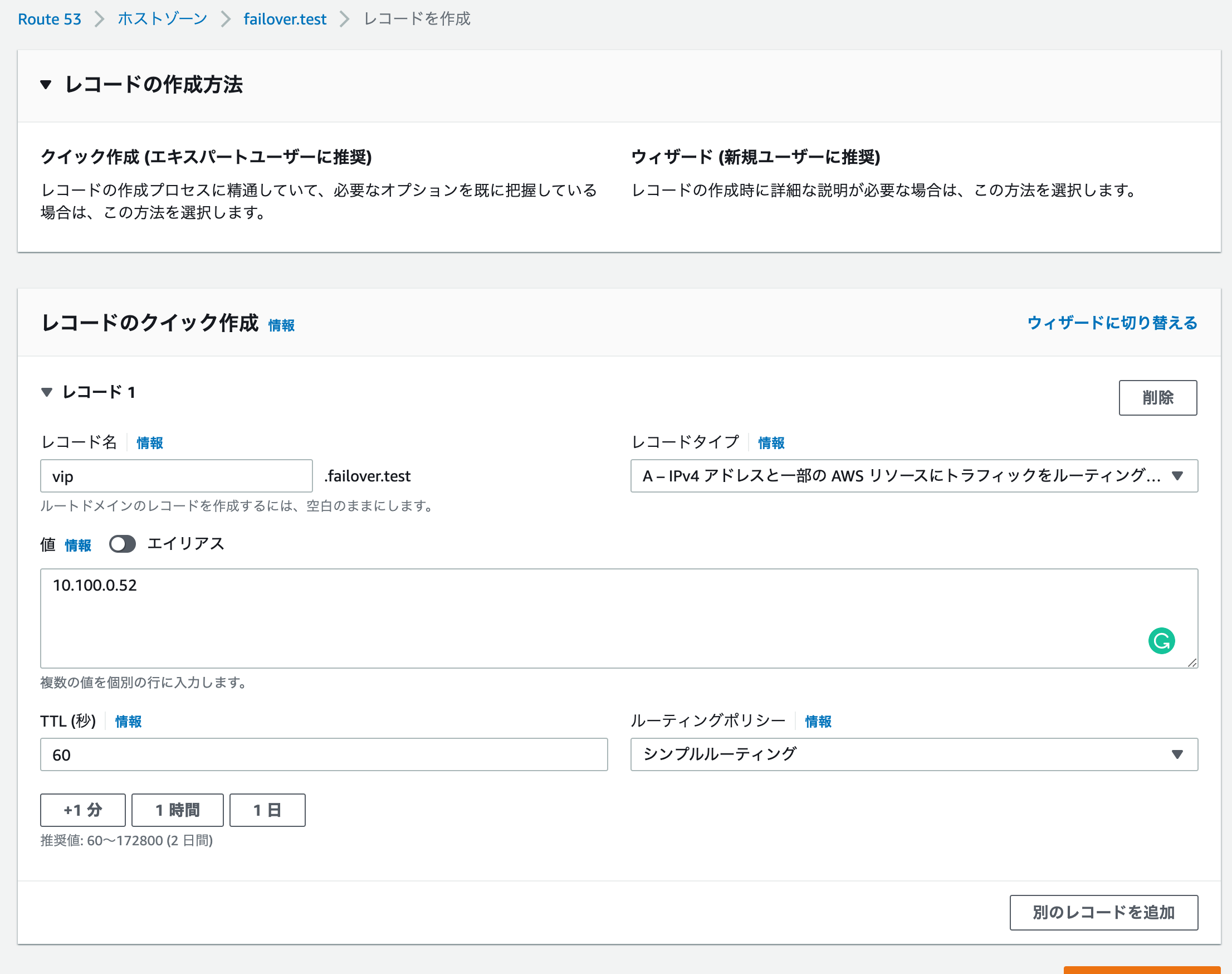
これで関連付けたVPC内でAmazon Provided DNS(デフォルトの)にfailover.testドメインの名前解決ができるようになりました。別途Route53 Resolver(VPCエンドポイントみたいなもの)を使うとDirect Connect等で接続している拠点からこのfailover.testドメインの名前解決ができます。
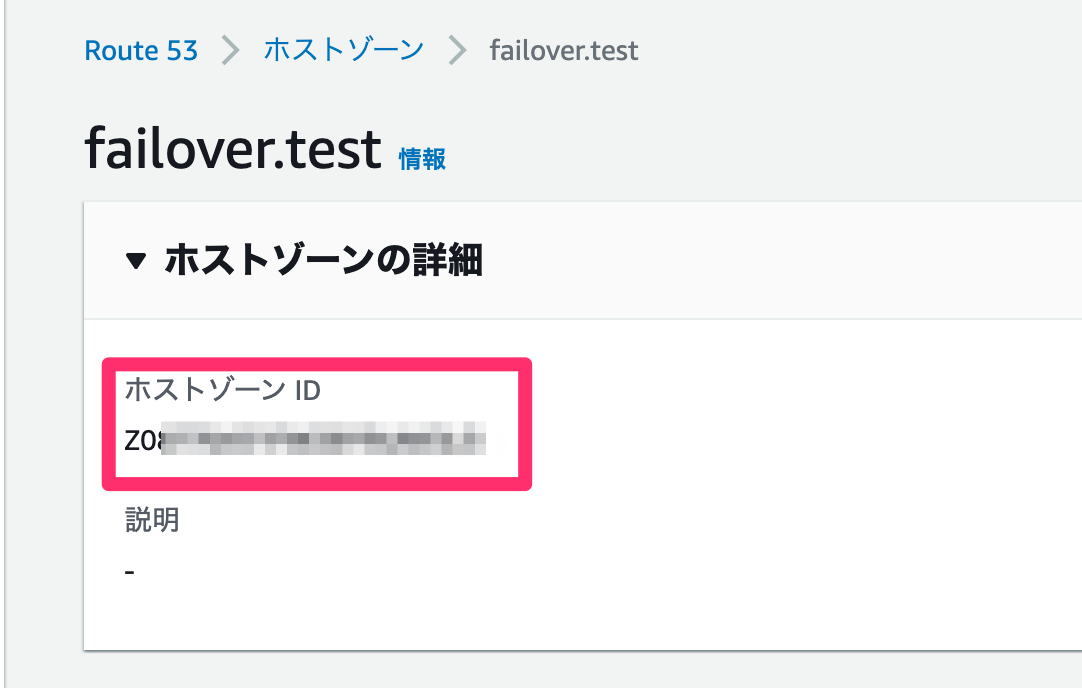
後続の作業のため、ホストゾーンIDをメモっておきます。
lambda作成
この後の流れはEIP方式と同じです。
新規にlambda関数をpythonで作成し、IAMロールにはAmazonRoute53DomainsFullAccessを付与したものを使用(本番では権限しぼってください)。コードを以下にします。
import boto3
import json
import os
def lambda_handler(event, context):
client = boto3.client('route53')
HOSTED_ZONE_ID = os.environ['HOSTED_ZONE_ID']
VIP_FQDN = os.environ['VIP_FQDN']
SECONDARY_IP = os.environ['SECONDARY_IP']
response = client.change_resource_record_sets(
HostedZoneId=HOSTED_ZONE_ID,
ChangeBatch={
'Comment': 'failover',
'Changes': [
{
'Action': 'UPSERT',
'ResourceRecordSet': {
'Name': VIP_FQDN,
'Type': 'A',
'TTL': 60,
'ResourceRecords': [
{
'Value': SECONDARY_IP
},
]
}
},
]
}
)
return {
'statusCode': 200,
'body': json.dumps(response)
}環境変数に先程のホストゾーンIDとFQDN、セカンダリインスタンスのIPアドレスを設定します。

あとはトリガーでEIP方式と同じようにEventBridgeを選択し、インスタンスの停止したときにこのlambdaが実行されるようにします。
TTLがうまいこと切れていれば数秒で切り替わります。
ELB方式
ELBのNLBを使った方式。Internal NLBのターゲットにプライマリインスタンスを設定し、障害時はセカンダリインスタンスをターゲットに追加、プライマリは削除する。
ヘルスチェックで切り替えないのはクラスタリングソフトから制御したいから。
実装例
NLB作成
まずターゲットグループを作成します。
ターゲットはプライマリインスタンスのみ、ポートは80番にしておきます。
その後、NLBを作成します。
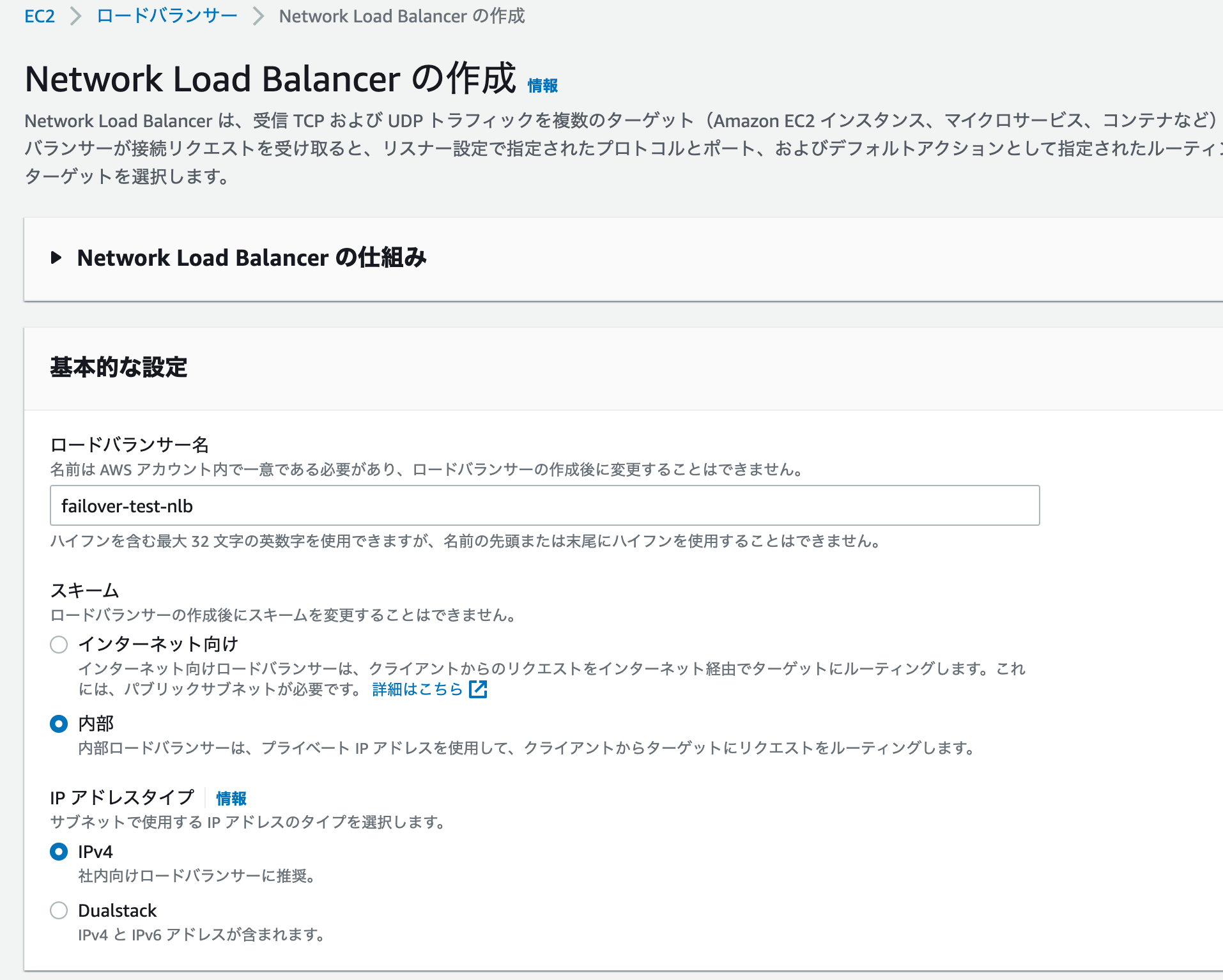
スキームは内部で、アドレスはIPv4。リスナーは80番ポートで先程作成したターゲットグループを指定します。
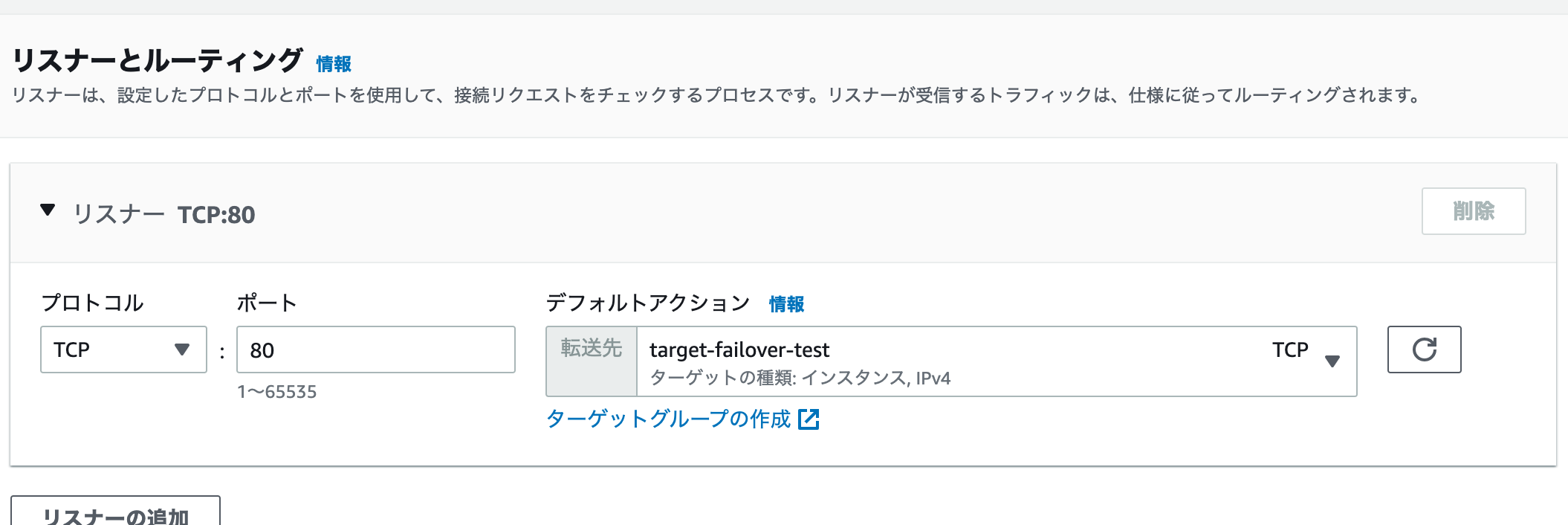
作成を押して数分待つとデプロイが完了します。
あとは他の方式と同じようにlambda等でboto3使ってインスタンスの障害時に切り替えるようなことをすればOKですが、NLB方式はおすすめしません。理由は以下で説明します。
NLBの仕様
NLBを作成するとこのような画面がでてきます。
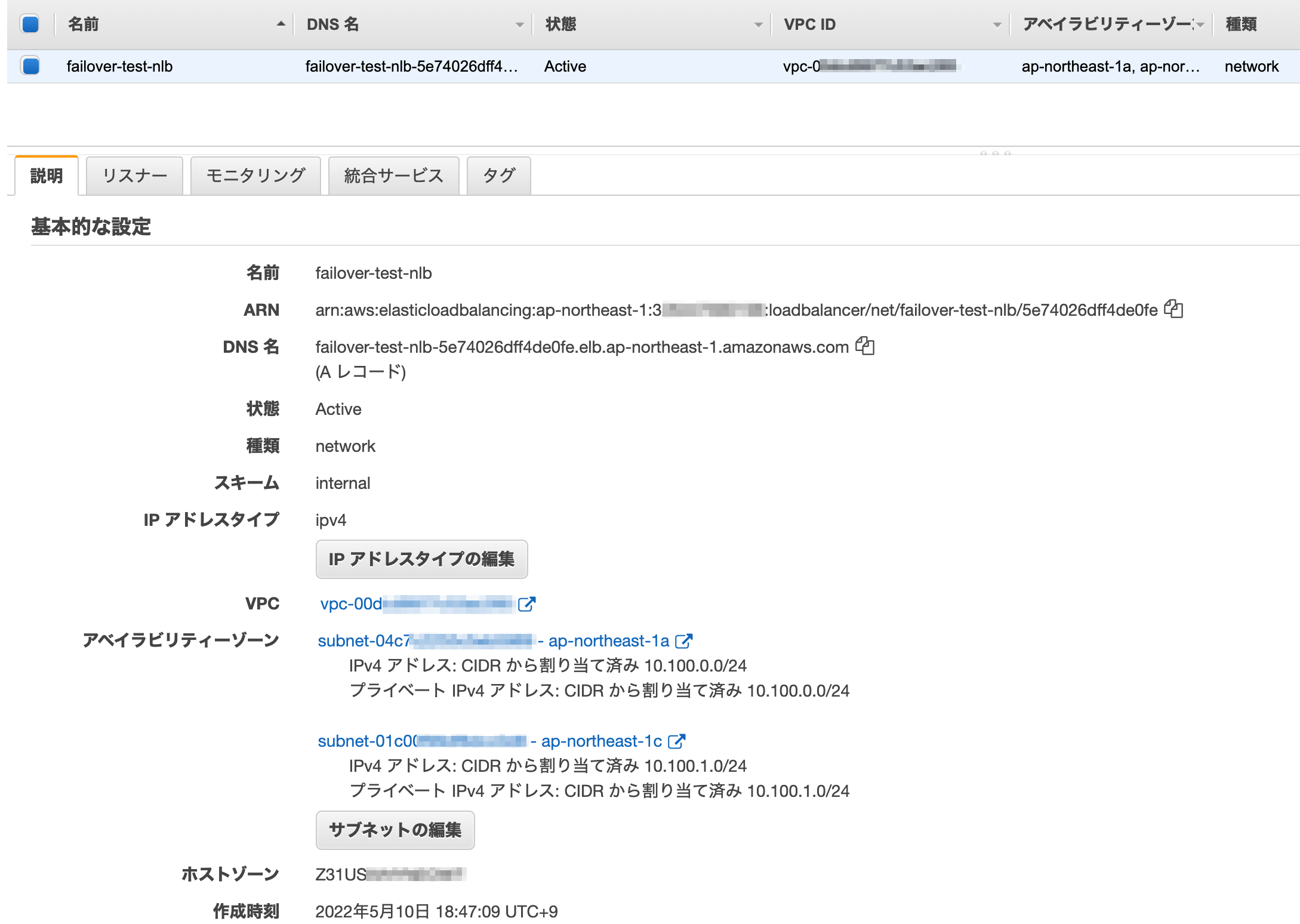
DNS名のところに書いてあるFQDNがこのNLBのエンドポイントとなります。NLBはターゲットのサブネットすべてにまたがる必要があり、今回は2つのサブネットにまたがせるのでこのFQDNを名前解決するとIPが2つ返ってきます。このIPは固定です。
どちらかのIPを仮想IPとして使いたくなりますが、そうはいかずFQDNを使ってアクセスする必要があります。

実はターゲットに片方のAZのインスタンスのみしかない場合、このFQDNはそのAZのサブネットのIPだけしか返さなくなります。

この状態では片方のIPはうまくいきますが、もう片方のIPではアクセスしても応答がありません。
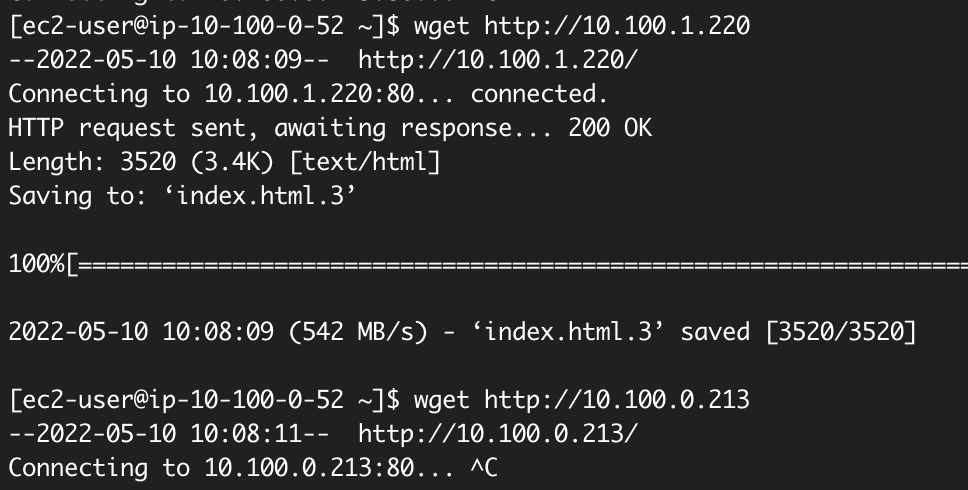
つまり、ターゲットのインスタンスが存在しているサブネットのほうのNLBに割り当てられたIPを使ってアクセスする必要があり、IPではなくFQDNを使う必要があります。
またリスナーやターゲットのところで使用するポートも1つずつ選択しなくてはならないので面倒です。さらにターゲットの中でインスタンスを削除したり登録するのにそれぞれ数分かかります。これらの点から仮想IPとして使用するにはELB方式よりもDNS方式のほうが優れています。
もちろんELBのヘルスチェックを使って切り替えたい、という場合はELBで良いです。
VIP方式
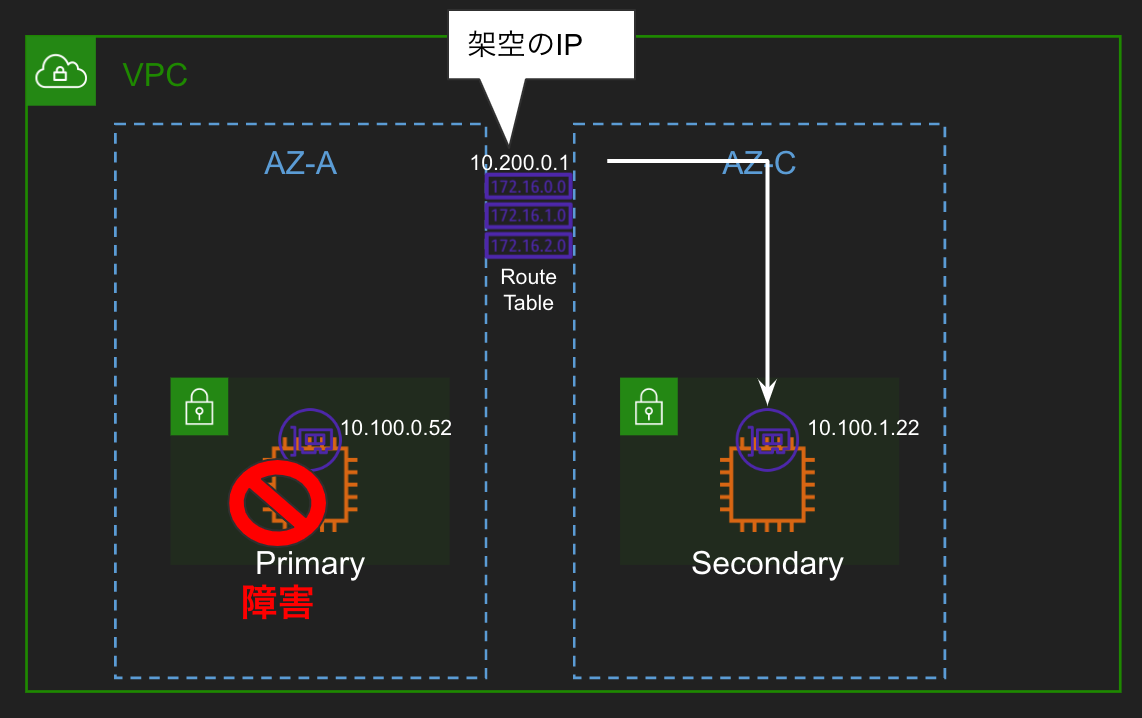
VPCやピアリングしているVPC、VPCやDirect Connectで接続しているCIDR以外のアドレス外のIPアドレスをVIPとして利用する方式。ルートテーブルでVIP宛のDestinationを通常時はプライマリインスタンスのENIにし、障害時にセカンダリインスタンスのENIに切り替える。 ルートテーブルはアクセス元のインスタンスが属するサブネットで使用されているものを用いる。
インスタンスに設定されているIPとは異なるIPでトラフィックが流れてくるのでOS側の設定も必要。またVPC外からVPCに対してVPCのCIDR外のアドレス宛の通信が来た際にドロップします。そのためこれはVPC内でのみ通信が完結する場合にのみ使用できるソリューションです。

実装例
ルートテーブル設定
VIPを10.200.0.1とします。10.200.0.1/32宛のトラフィックはプライマリインスタンスのENI宛というふうに設定します。

この状態でセカンダリのインスタンスから10.200.0.1宛にpingを打ってみましたが、プライマリのほうでパケットが届いておらず。。もしかしから今は使えないかどこか設定が間違っているかもしれません。

VPC内でしか効果がないなどデメリットも多かったので、あまり追求もせず今回はVIP方式はできなかったということにします。
EIP方式での実装と試そうと思っているのですがテストを実施したところタイムアウトになってしまい実行できません
他に確認するべきポイント等ありますでしょうか
EIP方式での実装と試そうと思っているのですがテストを実施したところタイムアウトになってしまい実行できません
他に確認するべきポイント等ありますでしょうか